|
|
| [Paper] | [Bibtex] | [GitHub] |
Overview Video
Abstract
Natural language-based communication with mobile devices and home appliances is becoming increasingly popular and has the potential to become natural for communicating with mobile robots in the future. Towards this goal, we investigate cross-modal text-to-point-cloud localization that will allow us to specify, for example, a vehicle pick-up or goods delivery location. In particular, we propose Text2Pos, a cross-modal localization module that learns to align textual descriptions with localization cues in a coarse-to-fine manner. Given a point cloud of the environment, Text2Pos locates a position that is specified via a natural language-based description of the immediate surroundings. To train Text2Pos and study its performance, we construct KITTI360Pose, the first dataset for this task based on the recently introduced KITTI360 dataset. Our experiments show that we can localize 65% of textual queries within 15m distance to query locations for top-10 retrieved locations. This is a starting point that we hope will spark future developments towards language-based navigation.
Motivation

|

|
|
|
|
|
|
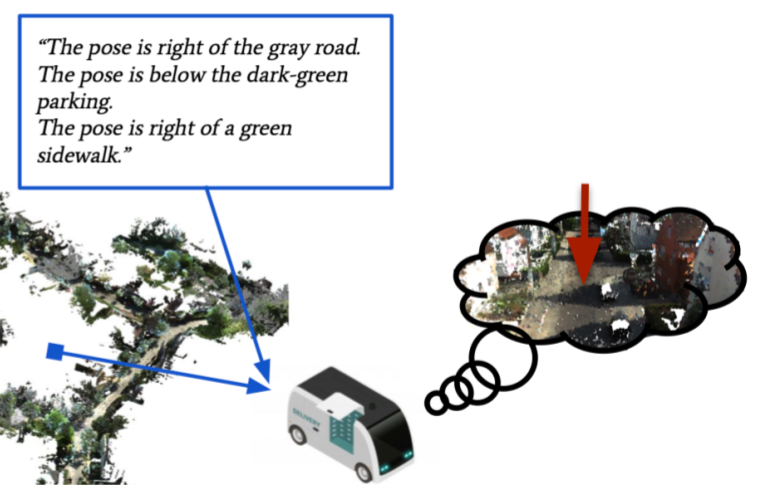
Specifying free-form locations for autonomous robots (pickup, delivery, ...) using natural language (a)!
We wish to extend AI-based localization to natural-language-based queries: Using a database of 3D RGB point clouds (a) and
text queries describing the objects relative to a pose (b), the task is to provide the most likely position estimate for the query (c).

|
Text2Pos: Text-to-point-cloud cross-modal localization CVPR 2022 [Paper] [Bibtex] [Github] |
Model overview
|
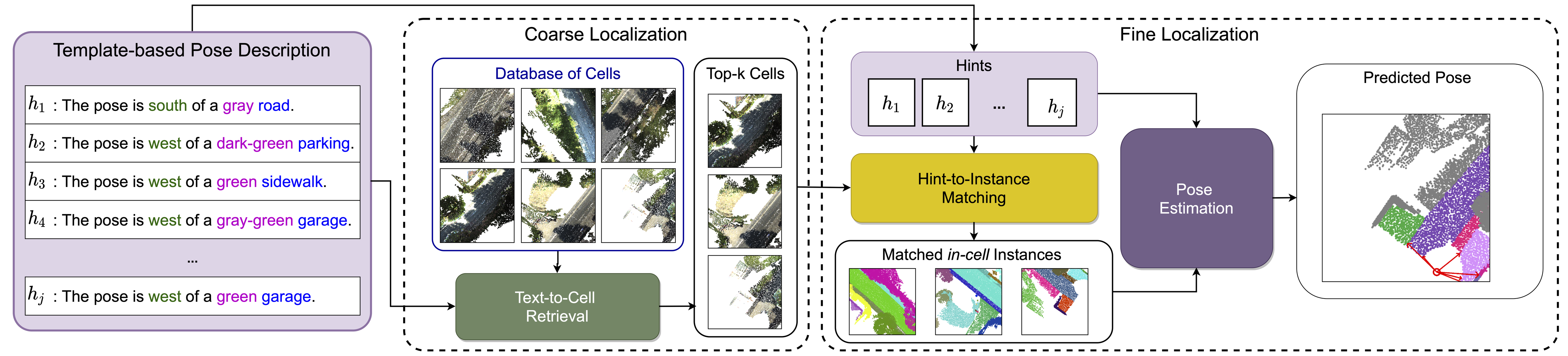
We present the first method for coarse-to-fine text-to-pointcloud localization.
First, we split the scene into rectangular areas ("cells") and train a joint text-cell-embedding to perform top-k cell retrieval (coarse).
Second, we match closely between instances mentioned in the query text and instances found in the top-k retrieved cells.
For each cell instance that is matched, we regress a translation offset vector between that object and the predicted pose to obtain a more accurate estimation (fine.)
Code
We make our dataset, model code and pre-trained models publicly available.
AcknowledgementsThis work was partially funded by the Sofja Kovalevskaja Award from the Humboldt Foundation.
|